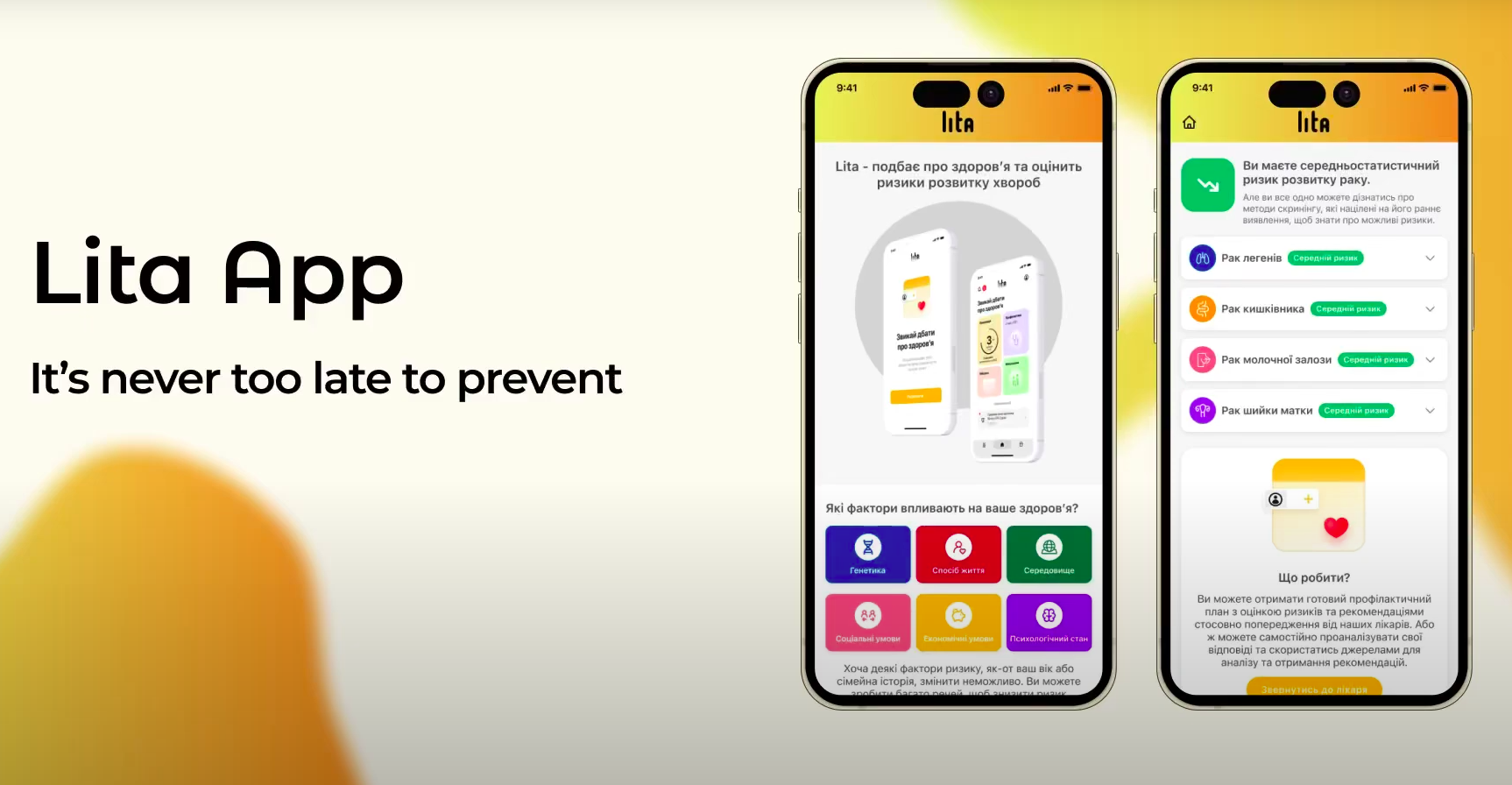
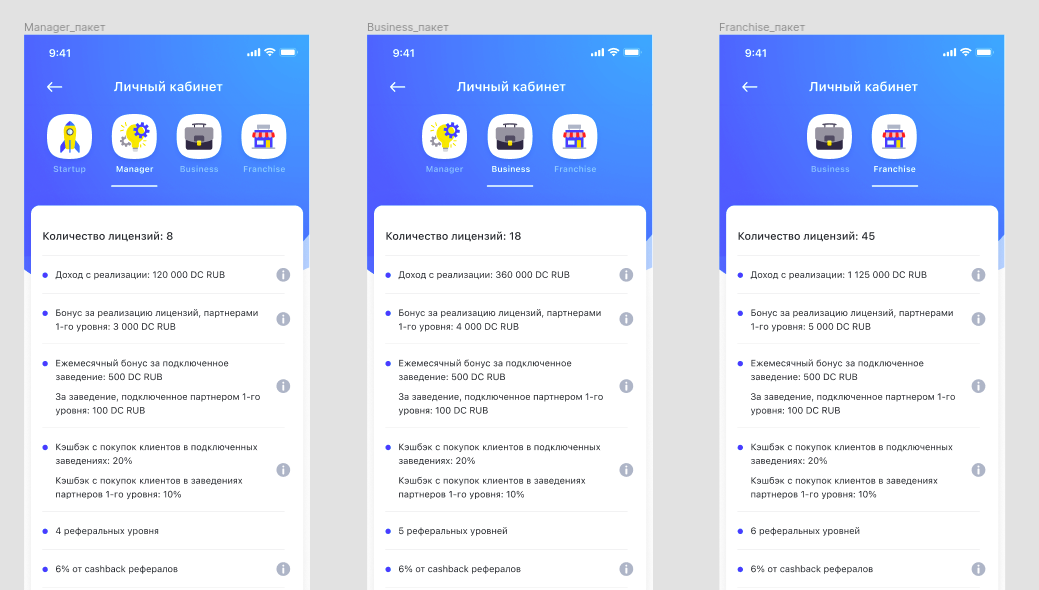
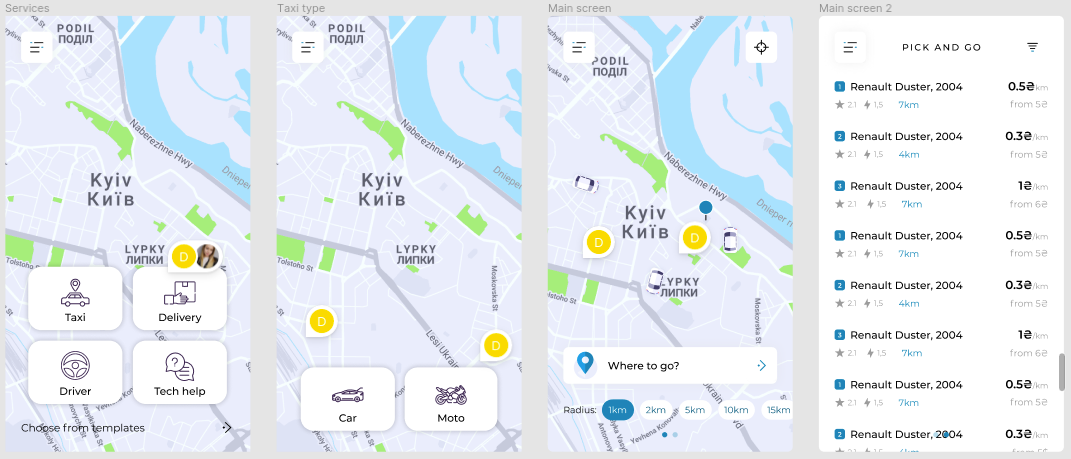
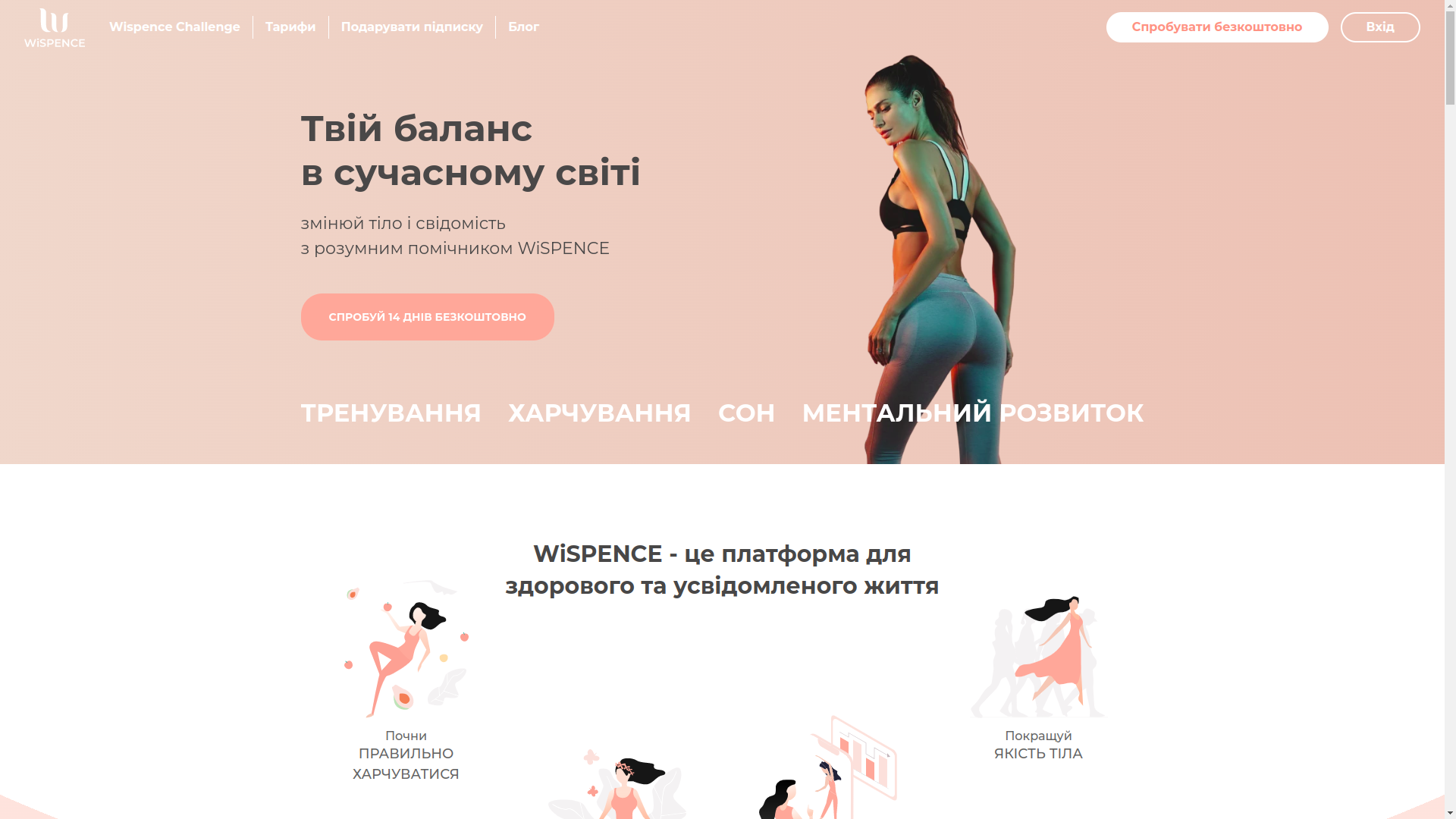
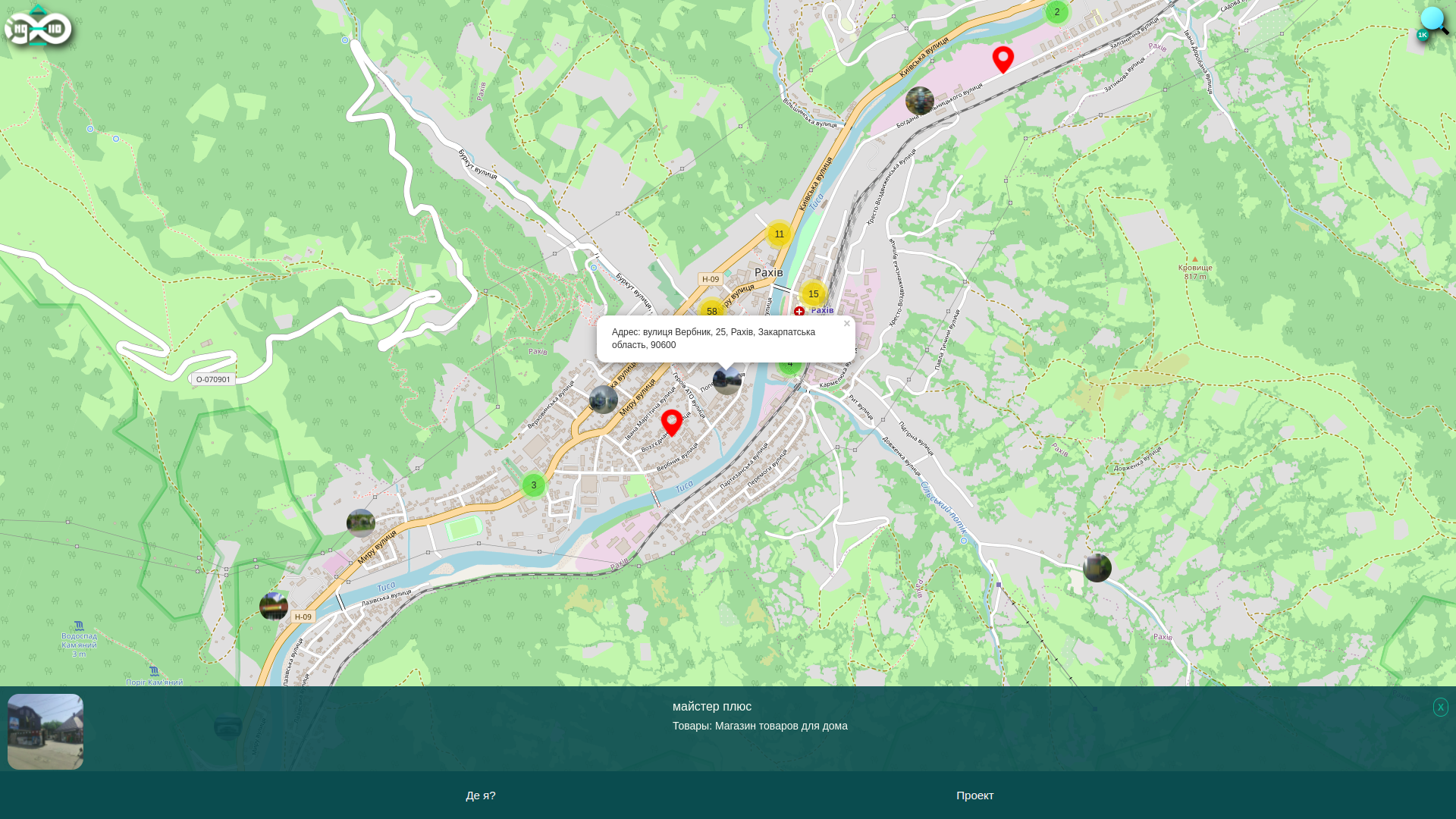
Разработка ПО
Разработка ПО
 Менеджмент
Менеджмент
 Для компаний
Для компаний
 Для стартапов
Для стартапов
 Архитектура ПО
Архитектура ПО
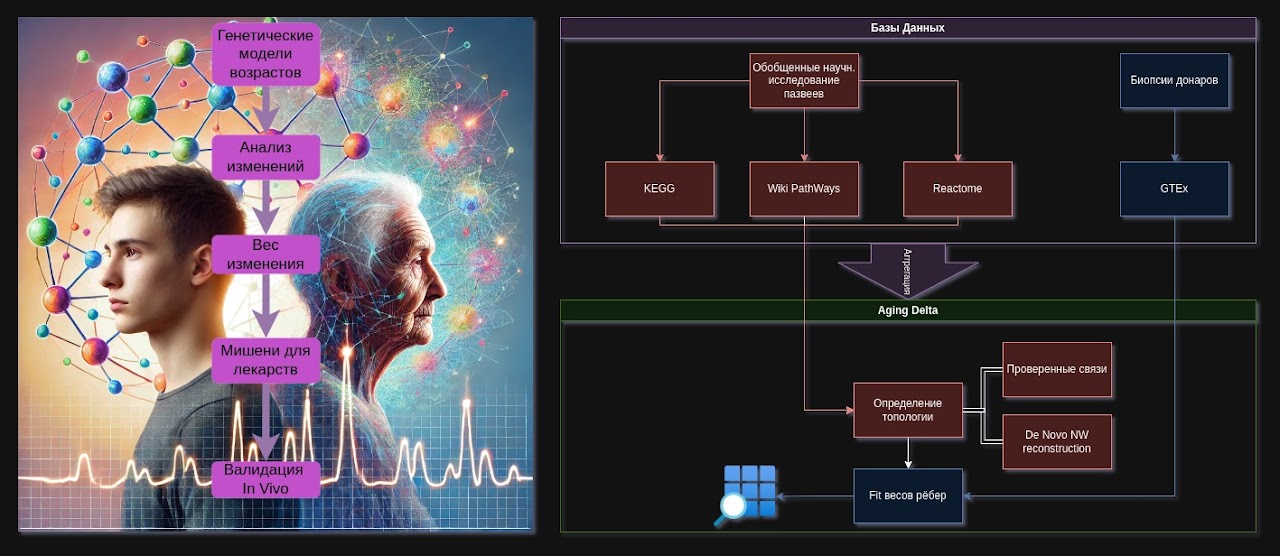
Совместно с Киевским Институтом Геронтологии, с кафедрой эпигенетики мы решили делать проект, направленный на научный способ сделать шаг в сторону радикального долголетия. Я приехал на экскурсию, мне показали лаборатории, после чего стартовали проект. Суть проекта - необходимо аггрегировать данные из различных генетических баз. Эти данные - -это экспрессия генов в различных тканях. Ткани брались посредством биопсии у различных пациентам (котоырх предстояло отсортировать по возрастным группам). Если по-простому, по-колхозному - суть проекта в том, чтобы найти отличия между данными пожилых и молодых людей, что позволит предположить, как мы можем замедлить старение.
https://sites.google.com/view/immortal-ingello/agi...
Проект Aging Delta нацелен на создание комплексной графовой модели изменений в биологических путях при старении, объединяя данные из ведущих баз знаний (KEGG, Reactome, WikiPathways) и реальных профилей экспрессии (GTEx). Архитектура проекта разделена на инфраструктурно-программную и биологическо-аналитическую части, предусматривающие сбор данных, их структурирование, построение графов, статистический/ML-анализ и, наконец, биологическую интерпретацию результатов. Использование методов доменно-ориентированного проектирования (DDD) помогает команде формировать единый язык (ubiquitous language) и эффективно взаимодействовать на стыке программирования, геронтологии и биоинформатики.
I.1. Общая концепция
- Описание
- Aging Delta — это междисциплинарный проект, ориентированный на исследование процессов старения на уровне генов, сигнальных путей и клеточных взаимодействий.
- Проект объединяет данные из нескольких типов ресурсов:
- Структурные базы знаний о путях (pathways) и сигнальных каскадах (KEGG, WikiPathways, Reactome), где хранится обобщённая информация о том, как взаимодействуют гены, белки и метаболиты.
- База данных реальной экспрессии (GTEx), содержащая результаты биопсий от разных доноров, что позволяет понять, насколько активно «включён» или «выключен» каждый ген в различных тканях и при разных возрастах.
- Цель
- Создать интегрированную сетевую модель (граф/графы) процесса старения с учётом возрастных изменений.
- Оценить вклад отдельных генов и путей (pathways) в развитие патологических процессов (онкология, нейродегенерация и др.) и сформулировать гипотезы о «таргетах» (конкретных генах/белках) для потенциальных вмешательств (модуляции).
- Задачи
- Агрегировать данные из структурных баз (KEGG, WikiPathways, Reactome) и сопоставить их с реальными данными экспрессии (GTEx).
- Построить два или более графов (для разных возрастных групп) либо один общий граф с различными весами (силами связей) в зависимости от возраста.
- Выполнить “фит рёбер” (определение силы взаимодействия/корреляции) на основе статистических или ML-методов (см. статью из PubMed, 37021935).
- Анализировать полученные сети с целью выявить ключевые изменения в сигнальных путях, их потенциальный вклад в возраст-ассоциированные заболевания и определить мишени для дальнейших исследований (например, белки, которые можно модулировать химически или эпигенетически — метилированием, ацетилированием, ингибиторами и т. д.).
I.2. Терминология и язык предметной области (Domain-Driven Design)
- Pathway (путь) — последовательность биохимических реакций или сигнальных событий (например, mTOR pathway, MAPK pathway и т. д.).
- Ген — участок ДНК, кодирующий белок или функциональную РНК.
- Белок (протеин) — продукт экспрессии гена, выполняющий структурные, ферментативные, регуляторные и другие функции.
- Экспрессия гена — активность гена в клетке (определяется количеством РНК или белка).
- Таргеты (targets) — потенциальные точки приложения, на которые могут воздействовать лекарства (например, гиперактивный белок, который нужно ингибировать).
- Метилирование/Ацетилирование — основные эпигенетические механизмы модуляции активности генов или белков.
- Граф — математическая модель сети взаимодействий, где узлы (nodes) — это гены/белки, а рёбра (edges) — их связи (корреляция экспрессии, прямые физические взаимодействия и т. п.).
- Фит рёбер — процесс подбора или вычисления «веса» взаимодействия между двумя узлами, основываясь на экспериментальных данных (например, из RNA-seq).
II. Структурные базы данных и GTEx
II.1. Структурные базы (KEGG, WikiPathways, Reactome)
- KEGG (Kyoto Encyclopedia of Genes and Genomes)
- Ссылка
- Содержит тщательно аннотированные карты путей, метаболизмов и информации о взаимодействиях между генами и белками.
- WikiPathways
- Ссылка
- Краудсорсинговая платформа, где специалисты и энтузиасты совместно поддерживают и обновляют пути.
- Reactome
- Ссылка
- База данных сигнальных путей с тщательной ручной аннотацией и ссылками на первичную литературу.
Из этих баз мы берём топологию (кто с кем связан) и общую информацию о функциональных взаимодействиях.
II.2. База GTEx (Genotype-Tissue Expression)
- Описание
- Ссылка
- Содержит «сырые» данные экспрессии генов (RNA-seq) из биопсий разных доноров, а также метаданные (возраст, пол, ткань и т. д.).
- Значимость
- Позволяет увидеть, как реально экспрессируются гены в разных тканях и возрастах.
- Данные нужны для «подгонки» веса связей (рёбер) в графе, а также для выявления паттернов, характерных для старения.
III. Архитектура и фазы
III.1. Разделение на две части
- Часть A. (Домен программирования и архитектуры)
- Сбор (возможно, с помощью скриптов и API) и очистка данных из баз.
- Организация хранения данных (БД, файловые хранилища).
- Реализация логики агрегации (усреднение, фильтрация, нормализация).
- Построение графов (структура + веса рёбер) для разных возрастных групп или одного общего графа с несколькими наборами весов.
- Визуализация сетей (JS/Canvas, D3.js или Cytoscape.js).
- Поддержка веб-интерфейса (управляющие панели, выгрузка/загрузка результатов).
- Часть B. (Био-химия, геронтология, статистический/ML-анализ)
- Применение методов статистики и машинного обучения (WGCNA, дифференциальная экспрессия, ко-экспрессионный анализ).
- Биологическая интерпретация полученных сетей: поиск ключевых модулей, генов, сигнальных путей.
- Формирование гипотез о таргетах (какой белок при старении проявляет гиперактивность или наоборот).
- Предложение стратегий модуляции таргета (ингибирование, активация, метилирование и т. д.).
- Финальная проверка результатов в биологических экспериментах (in vitro, in vivo).
III.2. Фазы проекта
- Фаза: Системный и доменный анализ
- Сбор требований, изучение предметной области, практики доменно-ориентированного проектирования (DDD).
- Фаза: Проектирование архитектуры
- Разработка схемы баз данных, определение форматов для хранения графов, протокол взаимодействия между Частью A и Частью B.
- Фаза: Создание прототипа
- Поднятие минимального окружения (Docker, сервер БД, PHP/JS-фронтенд).
- Импорт тестовых наборов данных (KEGG, GTEx).
- Фаза: Агрегация данных с учётом возрастных групп
- Разделение доноров в GTEx по возрастным когортам.
- Если нужно — объединение (усреднение) экспрессии внутри каждой возрастной группы.
- Создание (или обновление) графа (два графа «Молодой/Старый» или один с разными весами).
- Фаза: Нормализация данных (при необходимости)
- Устранение технических артефактов, приведение экспрессий к единому масштабу.
- Фаза: Усреднение экспрессий, дифференциальная корреляция или WGCNA
- Методика зависит от выбранной стратегии анализа (классическая дифференциальная экспрессия или построение ко-экспрессионных сетей).
- Фаза: Сравнение (pinpoint) для разных тканей
- Поиск изменений топологических свойств: потеря центральности, изменение кластеризации и др.
- Фаза: Оптимизация (по необходимости)
- Улучшение производительности (большие графы, обработка больших объёмов данных).
- Фаза: Визуализация
- Разработка интерактивных средств отображения (Canvas, D3.js, Cytoscape.js).
- Подсветка изменений между возрастами.
- Фаза: Статистический анализ и/или ML-методы
- Поиск закономерностей, кластеров, ключевых узлов.
- Использование алгоритмов обучения (классификация, регрессия, random forest, нейросети).
- Фаза: Мануальный био-клинический анализ
- Интерпретация результатов специалистами-геронтологами.
- Уточнение, какие пути реально связаны с онкологией, нейродегенерацией и т. д.
- Фаза: Построение гипотез о таргетах
- Формирование списка потенциальных генов/белков (например, гиперактивный белок, который нужно ингибировать).
- Фаза: Гипотезы модуляции таргетов
- Предложение конкретных вмешательств (ингибиторы, метилирование, ацетилирование) на молекулярном уровне.
- Фаза: Экспериментальная валидация
- In vitro эксперименты (использование клеточных линий, приборы: проточный цитофлуориметр для анализа, qPCR для подтверждения экспрессии, Western blot).
- In vivo эксперименты (модельные животные, наблюдение за изменениями фенотипа).
IV. Существующие проекты: сходства, отличия, синергия
- Human Ageing Genomic Resources (HAGR)
- Ссылка
- Содержит GenAge (база генов, связанных со старением), AnAge (данные о продолжительности жизни видов).
- Помогает выделить «кандидатные» гены для нашего анализа.
- AgeFactDB
- Ссылка (временно на реконструкции)
- База данных факторов, влияющих на продолжительность жизни разных организмов.
- Open Targets
- Ссылка
- Проект для поиска и приоритизации лекарственных мишеней, но не чисто про старение, а про болезни в целом.
- Aging.ai
- Ссылка
- Модель для предсказания возраста по биомаркерам крови, меньше фокус на сетевых путях.
- Geroprotectors.org
- База потенциальных геропротекторов, но без глубокой сетевой аналитики.
Все эти ресурсы дают частичную информацию (гены, продолжительность жизни, факторы), но не предоставляют комплексной «графовой» модели, которую мы хотим создать в Aging Delta.
V. Типовые проблемы и сложности
- Интеграция данных
- Разнородные форматы и идентификаторы (гены по Ensembl, HGNC, NCBI и т. д.).
- Возрастные срезы
- Часто нет чётких лонгитюдных данных по одному человеку, приходится усреднять по группам.
- Отсутствие реальной динамики
- Старение — процесс, а в базах мы обычно имеем статичные «срезы».
- Шумы и неполнота
- RNA-seq и другие методы дают варьирующие данные, необходима статистическая фильтрация.
- Интерпретация причин и следствий
- Связь гена с возрастом не означает причинно-следственную зависимость.
- Мультидисциплинарность
- Требуются компетенции в программировании, математике, геронтологии, биоинформатике.
VI. Технологический стек
VI.1. Программная (инфраструктурная) часть
- Операционные среды и инструменты
- Linux (серверное окружение), Docker (контейнеризация), Bash (скрипты автоматизации).
- Языки
- PHP (фреймворк Yii/Laravel) — бэкенд для веб-приложения.
- SQL (MySQL) — реляционная база данных для хранения агрегированной информации.
- HTML/CSS/JavaScript — фронтенд, визуализация через Canvas, D3.js или Cytoscape.js.
- Архитектурные решения
- Микросервисный подход или монолит с чётким разделением модулей (DDD — “bounded contexts”).
- REST API или GraphQL (опционально) для обмена с аналитическим модулем.
VI.2. Биоинформатическая и аналитическая часть
- Языки и библиотеки
- Python: pandas, NumPy, SciPy, scikit-learn, PyTorch/TensorFlow (для ML при необходимости).
- R: Bioconductor (edgeR, DESeq2, limma), WGCNA, iGraph.
- Подходы к анализу
- Дифференциальная экспрессия (DESeq2), ко-экспрессия (WGCNA).
- Построение корреляционных сетей, методов “фита рёбер” (статья PubMed 37021935).
- Графовый анализ: центральность, кластеризация, поиск модулей.
- Дополнительные инструменты
- Jupyter Notebooks/R Markdown — воспроизводимые исследования.
- Git — версионирование кода и данных.
VI.3. Дополнительные (маркетинговые) задачи
- Инфографика и схемы
- Создание промо-материалов (в Figma) для привлечения волонтёров, инвесторов.
- Схематическое объяснение архитектуры, принципа работы.
- Раздел сайта
- Агрегация информации о проекте, документация, FAQ.
- UX/UI-дизайн управляющих интерфейсов (просмотр графов, фильтрация, отчёты).
- Презентация
- Подготовка слайдов, постеров для научных конференций или питчей для инвесторов.
VII. Практики доменно-ориентированного проектирования (DDD)
- Ubiquitous Language
- Использование единых терминов (ген, путь, экспрессия, вес ребра, таргет) и понимание их одинаково командой разработчиков и биологов.
- Bounded Context
- Разделение проекта на модули:
- «Data Aggregation Context» (загрузка и нормализация данных),
- «Network Construction Context» (построение графов),
- «Biological Analysis Context» (WGCNA, статистика, ML),
- «Visualization & UX Context» (веб-интерфейс).
- Разделение проекта на модули:
- Context Mapping
- Определение, как эти модули взаимодействуют (API, форматы данных, промежуточные CSV/TSV или SQL-таблицы).
- Domain Events
- События, такие как «данные по возрастной группе обновлены», «граф пересчитан», «новый модуль сети обнаружен» — могут быть оформлены как доменные события, влияющие на логику проекта.
VIII. Ссылки и дополнительные материалы
- KEGG
- WikiPathways
- Reactome
- GTEx Portal
- PubMed (метод фита весов рёбер)
- Human Ageing Genomic Resources (HAGR)
- AgeFactDB
- Open Targets
- Aging.ai
- Geroprotectors.org
- Википедия (термины, определения)
https://docs.google.com/document/d/1eEL9kFAerWu-DW...
Это поможет разобраться с GTEx в исходном виде, делал для того чтоыб можно было ввести в курс дела, но это именно для того проекта которым занимаюсь, кроме того доки сыроваты, не самая черновая версия, полезная, но много чего не хватает. К ней прилагаются разные скрипты, но там их даже не запустить без отдельных доков на сами скрипты и инфру, а такого уровня доки только в голове и не на поверхности, вспоминать надо
https://docs.google.com/document/d/14C07ODWNKPZXAu...
https://docs.google.com/document/d/16ji4anrUO6zZA6...
Єто врядли пригодится