Разработка ПО
Разработка ПО
 Менеджмент
Менеджмент
 Для компаний
Для компаний
 Для стартапов
Для стартапов
 Архитектура ПО
Архитектура ПО
В ходе проекта была зафиксирована потеря порядка как минимум нескольких десятков тысяч долларов на разработку в ходе архитектурной ошибки, о которой расскажем в этой статье. Зато в ходе проекта были изобретены инновационные уникальные алгоритмы и приняты почти гениальные решения, которые со временем загладили потери посредством ускорения процесса разработки. Некоторые из этих решений тянут, как минимум, на отдельную подробную инженерно-техническую статью. По весовой категории проекта клиент совсем не приукрашивал сложность и интересность проекта, возможно даже недооценивал её, нам предстояла работа с действительно крупным и необъятным проектом в рамках новейших технологий и методологий.
Оглавление
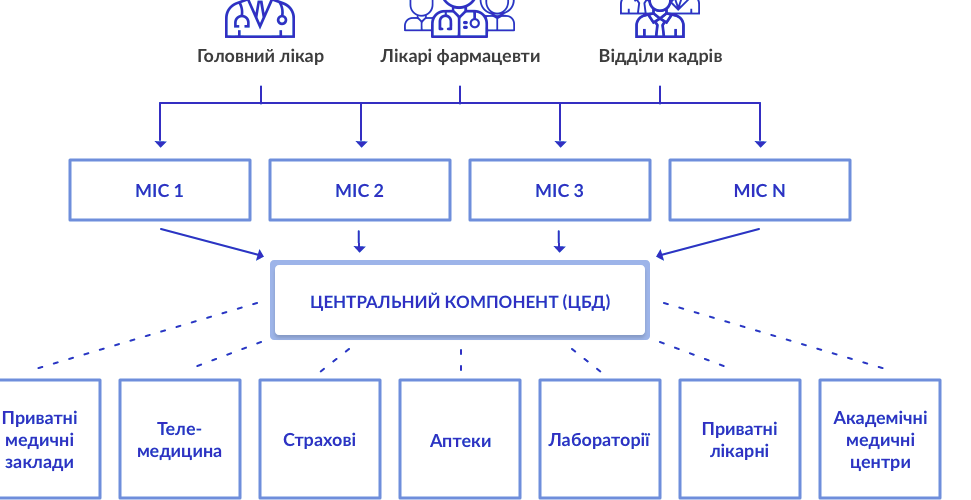
!!! В виду очень сложного договора о неразглашении в данной кейс-статье практически не будет изображений. Только визуализация общих фронт-решений.
Летом 2019 года к нам обратился технический директор немецкой компании GadFull с предложением привлечь нашу команду к разработке крупнейшего и инновационного проекта. В ходе разработки мы столкнулись с вызовами и задачами, некоторые из которых мы до сих пор считаем самыми сложными за всю историю нашего проектирования и программирования.
Кратко: GadFull - ТОП 1 бренд, партнёр компании Amazon, в нескольких странах лидер по разным направлениям - смартфоны, аккумуляторы, орг-техника и расходники, инструменты, товары для дома. Сотни тысяч клиентов, тысячи отзывов, штат аналитиков, сложнейшие бизнес-процессы.
Через несколько лет клиент планирует получить многофункциональную платформу мониторинга, частично управляемую искуственным интеллектом. Всё просто (нет).
На первое время была поставлена цель - запуск системы под названием “ЕВА”. Говоря по-простому - необходимо, чтобы часть работы делали не сотрудники, а робот. Говоря предметно - для регулярного сбора, мониторинга и анализа данных конкурентов и клиентов компании с целью автоматизации операционных решений в рамках целевых показателей эффективности.
Конечно, вдаваться в конкретику и нюансы, в виду NDA, не получится, но суть такая: сотрудники отдела аналитики и топ-менеджеры компании должны иметь инструмент, круглосуточно, бесперебойно и автоматизировано собирающий данные из различных ресурсов, отображающий эти данные, позволяющие работать с этими данными, строить графики, сводные таблицы, строить сложные объединения и фильтры. Также система позволяет устанавливать различные цели (в числовых конкретных показателях) и исходя из этих целей будут возникать те или иные задачи для различных отделов компании и внештатных сотрудников.
Сложный майнинг данных
Одним из существенных вызовов было то, что амазон всячески блокирует возможность сбора такого рода данных даже для своих партнёров, но предоставляет специальный программный интерфейс для некоторых данных. Этих данных не достаточно для целей компании.
Потому это не только парсинг, но скорее сложный майнинг с обходом интеллектуальных блокировок различными средствами, это анализ функционирования серверов амазон, при том что доступа к исходному коду амазона, естественно, нет. Нужно вообразить и восстановить алгоритмы работы амазона по очень косвенным признакам.
Технически и юридически собирать данные не запрещено, потому амазон усложняет это до невероятного уровня, таким образом большинство конкурентов и их штаты программистов не могут получать нужные данные, ведь это задача не для среднячка и даже не каждый опытный программист справится с этим, требуется не только умение писать межсервисные запросы, но и умение проводить глубокий анализ HTTP заголовков, сопоставлять его с временными интервалами, использовать специальные инструменты наподобие анализаторов трафика...
Нашей задачей было убедить сложные анти-бот алгоритмы амазона, что мы человек, то есть написать полноценную программу симуляции пользовательских, якобы “человеческих” действий. Как мы это сделали совместно с очень опытным техническим директором, с которым работали в команде - это коммерческая тайна и крайне-интересный опыт.
Синтаксический анализ данных маркетплейсов
После получения данных всё только-только начинается. Ведь эти данные были предназначены совсем не для чтения человеком. Эти данные необходимы для анализаторов стандартных браузеров и содержат 98% мусора, необходимого для корректного отображения и позиционирования их на странице.
Чтобы найти необходимую информацию, необходим сложный синтаксический анализ. В отличии от программных интерфейсов, где всё подаётся “на блюдичке” в относительно удобном XML дереве, тут за каждый байт информации необходимо бороться, каждая цифра отвоёвуется посредством написания и отладки специфичных функций.
В требования к алгоритмам также входила необходимость устойчивости оных. Т.к. еще одной спецификой такого гиганта, как амазон, есть то, что он постоянно “выкатывает” новые изменения. И если написать алгоритмы “спустя рукава”, они могут отработать сегодня, а завтра уже быть бесполезными. Они должны работать практически интеллектуально, анализируя полученное сырьё с разметкой и данными так, как анализирует их человек.
И даже при профессиональном подходе иногда мы сталкивались с необходимостью корректировать эти алгоритмы. Да что там говорить, иногда даже живому разумному человеку бывает сложно отыскать необходимые данные в свете всех фильтров и зонирования. Кто работал, меня поймёт =)
Производительность труда
За 5 дней в систему добавлялось огромное количество кода благодаря команде разработчиков. Речь идёт не о черновиках, а об отлаженном и оптимизированном коде, который соответствует сложным требованиям к качеству.
Наследие старых проектов (легаси)
Еще одним пунктом сложности, хоть и не самым существенным, было то, что компания имела множество различных форматов, отчётов, алгоритмов и программных наработок, которые позволяли им работать до сих пор. Это нормально и ожидаемо. Но в свете огромного объёма и сложности приходилось часами общаться с представителями компании, изучать не только их наработки, но и некоторые аспекты их работы, так как то что было для них само собой разумеющееся, для нас было тёмным лесом. Однако, для нас это нормальный процесс, мы с любопытством вникали во все тонкости, задавали вопросы, иногда даже вносили свои свежие идеи, которые удивляли как боевых опытных сотрудников, так и собственников, с которыми мы также имели возможность говорить (один из собственников говорил на русском языке, потому мы легко понимали друг-друга).
Инфраструктура
Необходимо сказать пару слов об инфраструктуре. Конечно, в рамках дозволенного и не секретного. Для создания инфраструктуры был привлечён отдельный специалист-архитектор и DevOps. Система деплоя и доставки разворачивалась с использованием платформы для оркестрации контейнеров Kubernates и сервером автоматизации Jenkins. Конечно, был использован Docker для целей девелопмента и тестирования, были введены дев-сервера, стейджинг и продакшн. В качестве системы контроля версий использовался git на базе премиум аккаунта github. Сервера были настроены на базе Digital Ocean.
Была разработана документация, пользуясь которой мы заходили в аккаунт Jenkins и управляли доставкой, мониторили статус развёртывания, поднимали новые микросервисы, управляли хуками, работали с конфигурациями сервисов, настраивали фоновые процессы и многое другое. Было множество неочевидных нюансов в ходе построения инфраструктуры, о которых, увы, нужно умолчать.
Микросервисная архитектура
Почти всегда, обращаясь к нам, от нас ожидают глубокой экспертизы не только в программировании, но и в выборе ключевых для бизнеса технических решений - то есть архитектурных решений. Именно этим занимается технический специалист высшей квалификации - системный архитектор.
Данный проект также ждал от нас ответственных технических решений, но одно решение нам было продиктовано изначально - это микросервисная архитектура.
Исходя из вводных данных, нами было оспорено данное решение в пользу разработки изначально модульной системы, системы слоёв, концентрации усилий на создании и тестировании отчётливой и нормализованной модели предметной области в качестве ядра и опоры системы и всего проекта. В дальнейшем систему можно было бы разделить по контекстам и вычислить удобные “линии” разграничения на микросервисы. То есть мы отрицали удобство того, что называют “microservice first”.
Однако решение по микросервисной архитектуре было уже принято и в виду того, что мы могли не знать некоторых нюансов и тонкостей в дальнейших целях компании (а изучить такой объём за первые консультации не представлялось возможным) мы приняли идею разработки системы начиная с микросервисной архитектуры. В команду был привлечён опытный архитектор, задача которого была расщепить систему на микросервисы и проконсультировать по вопросу их связки. Архитектор с нашей стороны отвечал за так называемую архитектуру интерьера, которая была ближе к предметной области и объектно-ориентированному анализу.
Также мы утешали себя тем, что в некотором смысле мы не делаем микросервисы с нуля, ведь у компании уже было немного рассредоточенные наработки программного обеспечения в виде огромных алгоритмов, которые прилагались к системе электронных таблиц, а также была немного денормализованная база данных и так называемый легаси код на Zend Framework (сейчас это не является коммерческой тайной в виду замены решения). Позже выяснилось, что переиспользовать и “отрезать” от этих наработок микросервисы не представлялось возможным. Наработки служили скорее прототипом, чем переиспользуемыми подсистемами и уж точно не могли стать микросервисами.

Как и было спронозировано, проблемы с микросервисами возникли. Нельзя сказать, что в этом была вина архитектора-консультанта или технического директора, т.к. методологически было сделано всё правильно, решения по проектированию микросервисов принимались сообща, всей командой (не только командой с нашей стороны, но и всей командой со всеми привлеченными экспертами, с штатными сотрудниками компании) но в целом это было ожидаемо, т.к. ошибкой было начать с микросервисной архитектуры, а не прийти к ней постепенно, органично.
Опять же, не получится описать во всех деталях ключевые проблемы, но общая суть была в том, что на стартовом этапе было невозможно точно определить границы микросервисов (это самая сложная задача и обычно это вычисляется эмпирически, посредством наблюдения). Таким образом, чтобы перейти от проектированию к программной реализации, разделение было проведено логичным и очевидным образом, исходя из модулей, которые вырисовывались и, можно сказать, напрашивались, глядя на огромную отрисованную схему системы “ЕВА”.
Но на практике, когда начали расписываться все алгоритмы системы, оказалось, что некоторые микросервисы имеют очень большое количество связей. Особенно по части сложных сводных таблиц со сложной фильтрацией. Таким образом получилось так, что очень многие алгоритмы, которые берет на себя СУБД и содержит их под капотом, теперь было необходимо выносить наружу и переписывать при склеивании данных вручную, т.к. если бы мы не поддерживали отдельные изолированные базы данных для каждого микросервиса персонально - мы бы нарушили идею микросервисной архитектуры как таковую. Либо же дублировать схемы данных от микросервиса к микросервису и получить кучу тасков на написание алгоритмов сложной и нетиповой синхронизации. Альтернативным вариантом было введение шины, в которую можно было поместить ключевую логику объединения множеств, но при подсчётах выяснилось, что в сумме вся эта логика породит достаточно жирный центровой сервис. То есть самым оптимальным решением было действительно писать монолит изначально и отрезать в микросервисы только необходимую и слабо-зависимую функциональность.
Так или иначе, на определенном этапе мы осознали ошибку и вынуждены были признать, что достаточно существенный бюджет был потерян безвозвратно. Но несмотря на это, мы смогли написать сложнейшие объединяющие алгоритмы и система работала. В ходе работы получился в некотором роде микросервисный фреймворк общего назначения, который медленно и постепенно будет компенсировать данную потерю, т.к. цели изоляции определенной функциональности были достигнуты, пусть и не такой малой кровью, как изначально думал заказчик.
Микросервисный фронтенд
Да, фронтенд мы также планировали микросервисным. И если на микросервисный бекенд на момент старта проекта были сложены более менее хорошие и понятные практики и методологии, то по фронтенду всё было неоднозначно. Мы изучили ряд решений, в частности решение, которое помогало создавать действительно изолированные решения на различных фреймворках в рамках одной системы. Самой тонкой частью, как и на бекенде, было пересечение функциональных элементов. В нашем случае это глобальные компоненты, которые отвечают, например, за меню, леяут, фильтры (которые применяются глобально ко всем данным, например можно было переключиться только на срез данных одного маркетплейса и\или в рамках выбранного диапазона дат (и не только) и тогда всё приложение, все таблицы и графики будут показывать данные исключительно исходя из этих глобальных настроек) и таких фильтров было на момент разработки 4, а в будущем это могло расшириться. Менее очевидные (технические) глобальные функции системы, такие, например, как роутинг - также было не совсем понятно - как хранить и поддерживать. Были спроектированы абстрактные объектные интерфейсы, которые декларировали способ поставки правил роутинга каждым независимым микросервисом.
Некоторые микросервисы было решено показывать через айфреймы, несмотря на все минусы и нюансы такого подхода, о которых мы были осведомлены. Потому только малозависимая от общего состояния фронтенд-приложения функциональность была отображена таким образом.
Сервис мониторинга и настройки мониторов
Приложение содержало достаточно сложную функциональность мониторов. Визуально один монитор - это карточка, которая отображает в графическом виде состояние некоторого среза данных. И эти карточки были не заданы изначально. Их можно было создавать и настраивать принцип среза. То есть видеть состояние определенного продукта или группы продуктов на определенном маркетплейсе, их динамику изменения цены, динамику добавления комментариев, динамику изменения спроса а также производные всех перечисленных (и не упомянутых) способов рассматривать ситуацию на рынке. Монитор строился на свежих и актуальных данных и учитывал глобальные фильтры, о которых было выше.
Монитор был базовой единицей для аналитики и из таких мониторов аналитик мог построить свой собственный уникальный экран, позволяющий ему принимать различные решения - от переоценки товара или групп до закупки рекламы или отсылки товара на обзор блогерам.
Кастомный и гибкий REST-like протокол
В ходе разработки приложения нашей командой был разработан уникальный протокол. Предыдущие наработки включали в себя GraphQL, однако данный протокол не использовался даже на половину его функций, а иногда его использование только переусложняло запросы в виду не чётко продуманной формализации реквестов. Потому от этого протокола мы отказались, прости Фейсбук.
Наш протокол идеально подходил именно под данную систему и был спроектирован исходя из тех запросов, которые подразумевались уже сейчас - как между микросервисами, так и клиент-сервреные запросы. Что также важно, протокол учитывал некоторые запланированные на будущее функции системы, которые были спрогнозированы вместе с отделом аналитики и техническим директором. Протокол учитывал вышеупомянутые глобальные фильтры, имел гибкость управления (например, позволял строить сложные запросы с объединением множеств или группировкой, что позволяло без дополнительного программирования внедрять новые функции на фронтенде). Уникальной возможностью протокола был параметр запроса, который позволяет сделать запрос в один микросервис и скомандовать ему сделать объединение данных с другим микросервисом. Подобные изобретения были местными ноу-хау, т.к. подобной функциональности в готовом виде мы не нашли. Важно понимать, что протокол был не просто идеей и форматом. Это была группа достаточно хитрых алгоритмов, которые обеспечивали его работу. Целью протокола было существенное ускорение разработки в условиях гетерогенности среды и разнообразности форматов данных. Протокол подводил всё под единый знаменатель и задавал дисциплину разработки, отчётливость архитектуры, наглядность программных интерфейсов. Конечно, протокол был хорошо продокументирован и само-собой содержал правила безопасности (такие как белые списки), которые не позволяли запрашивать фронтенду и другим микросервисам данные, на которые не имелось разрешения в рамках авторизации.
HATEOAS
https://ru.wikipedia.org/wiki/HATEOAS
Одним из наследий REST протокола было применение гипермедиа запросов. Это позволяло в рамках ответа выдавать дополнительные данные о запрашиваемом ресурсе, например запросы, которые поддерживались в рамках этого ресурса. Это позволяло воплощать интересные задумки, такие как автоматизированный и единый способ строить таблицы данных и графики, таким образом, например, на фронтенде (преимущественно React Redux) была написана функциональность, которая не хардкодила все действия с множеством данных, а автоматизированно выводила его исходя из гипермедиа. Это привело все типовые рендеры данных к единому формату и избавило от огромного количества лишнего кода. Фронтендеры, поняв данный аспект архитектуры, много раз восторжено переспрашивали - “А что, так всегда можно было? Почему мы раньше так не интегрировались!”. И их можно понять, ведь это снимало с них много рутины. Но мы только добираемся до самого интересного…
Метаданные
Это самое интересное изобретение в рамках этого проекта. Еще на старте, благодаря этапу анализа и проектирования, архитектором было замечено, что существенная часть данных в проекте имеет достаточно типовые оболочки для отображения. Приложения создавались для аналитиков, а им, в отличии от клиентов, не нужны пёстрые и минималистичные интерфейсы. Наоборот, им нужно чтобы данных на странице было много, чтобы эти данные были точные, интерфейс работал быстро и точно и чтобы похожие вещи имели похожий способ отображения. Таким образом очень многие данные отображались в насыщенных многофункциональных таблицах-гридах и были сопряжены с различными графиками на двумерной плоскости. Да, были и другие способы отображения (те-же мониторы). Но преимущественная часть отображалась в таблицах и графиках.
Первое, что приходило на ум - это стандартизировать таблицы, таким образом были спроектированы многофункциональные полиморфные гриды. Их многофункциональность заключалась в том, что они имели функции сортировки, пагинации, сложной фильтрации, выгрузки, настройки колонок, их размеров и местоположения. Их полиморфность заключалась в том, что в зависимости от контекста, таблицы могли отображать различные дополнительные функции и фильтры - диапазоны, множественные чекбоксы и прочее. Также таблицу было легко расширить, добавив в неё уникальные управляющие элементы, которые имели смысл только для определенных наборов данных. Хотя это может показаться банальным экспертам, которые разрабатывают административные интерфейсы и сложные корпоративные учетные системы, для программистов фронтенда это было настоящим подарком, так как они заметили существенное упрощение работы, немного помучившись с воплощением полиморфизма в таблице. Они поняли суть всех связанных компонентов (а аналитический грид - это десятки созависимых объектов-компонентов) и открыли для себя полиморфизм заново.
Далее мы углубились в предметную область и саму суть системы, которую мы создаём. Нашей командой был продуман и воплощен механизм метаданных. Сами данные хранились, преимущественно, в реляционных хранилищах своих микросервисов. Но эти данные поддавались сложной фильтрации, валидации, сложным правилам добавления новых данных в эти таблицы через фронтенд.
Обычно, эти правила валидации прописываются в виде отдельных функций на фронтенде, дублируются на бекенде, нужно писать лишний код, да еще и на двух языках. Немного лучше дело обстоит в изоморфных приложениях, где, если всё делать правильно, логика валидации пишется на одном языке единожды и не дублируется на бекенде и фронтенде. Однако, в любом случае функции валидации пишутся хардкодом. В лучшем случае, эти правила организованы в виде декларативных стейтментов, что упрощает их переиспользование (например при вводе данных в инпут фильтра и вводе аналогичных данных в, как бы, аналогичный инпут при заполнении формы добавления некоторого объекта). Мы пошли еще дальше. Мы создали универсальные хранилища метаданных, такие метаданные каждый микросервис может поставлять в виде информации о себе. Валидация - это яркий и наглядный пример, но также там были и другие данные, необходимые как для технических нужд, так и для нужд фронтенда. В метаданных мы хранили уникальные настройки таблицы - размеры. позиционирование, положение ячеек, ввели типы данных, правила валидации, некоторые предустановленные кондишены, а главное - мы привязали это к определенному пользователю. Что это дало? Во первых - очень многие тонкости можно было настроить без программиста и не зная программирования - например размеры и внешний вид таблиц (и графиков тоже), логику проверки данных, их типы (например, если тип свойства множества “дата” - то при добавлении этих данных или при использовании формы фильтров в таблице эти данные будут отображаться в виде дата-пикера, проходить валидацию на единый для всей системы формат даты). Также можно было добавлять кастомные правила - и тоже без программистов. Дополнительным удобством стала возможность для аналитика настроить таблицу с предустановленным фильтром. То есть, например, Вася смотрит таблицу продуктов отсортированную по дате, а Пете удобнее проводить анализ в продуктах, отсортированных по алфавиту - это можно настроить. И одна и та же таблица для разных пользователей будет соответствующая его удобству.
В сумме с протоколом и описанным выше механизмом гипермедиа мы получили супер-умные таблицы и существенно, порядково сократили время, которое необходимое для разработки и создания новых таблиц. Важно отметить. Не в любом, далеко не в любом проекте уместно создавать такой конструктор. Ведь вы рискуете потратить уйму времени на разработку универсальной функциональности, которая не будет переиспользуема. Для такого смелого шага необходимо проводить анализ требований и не только нынешних, но и потенциальных - на годы вперёд. В данном проекте было очевидно, что создание такой функциональности метаданных создаст необходимую дисциплину девелопмента и сэкономит много времени и сил на разработку.
В проекте были и другие интересныие и инновационные изобретения, но т.к. они были разработаны либо другой командой и другим архитектором, либо совместно и без личного авторства - данные решения описаны не будут.
На описание и даже частичное не конкурирующее использование в других проектах (только основного ядра метаданных, без привязки к данной предметной области) вышеописанных изобретений было получено официальное согласие от руководства проекта.
Выводы: архитектор проекта способен сэкономить Вашему проекту большие деньги. Игнорирование мнения архитектора чревато потерей денег. Отсутствие архитектора в сложном проекте делает шансы на его разработку минимальными. Скорее всего система будет работать не так, как ожидается и со временем будет запроектирована и переписана с привлечением специалиста по архитектуре.
Обращайтесь к нам за подробной консультацией перед стартом проекта - это бесплатно и информативно.