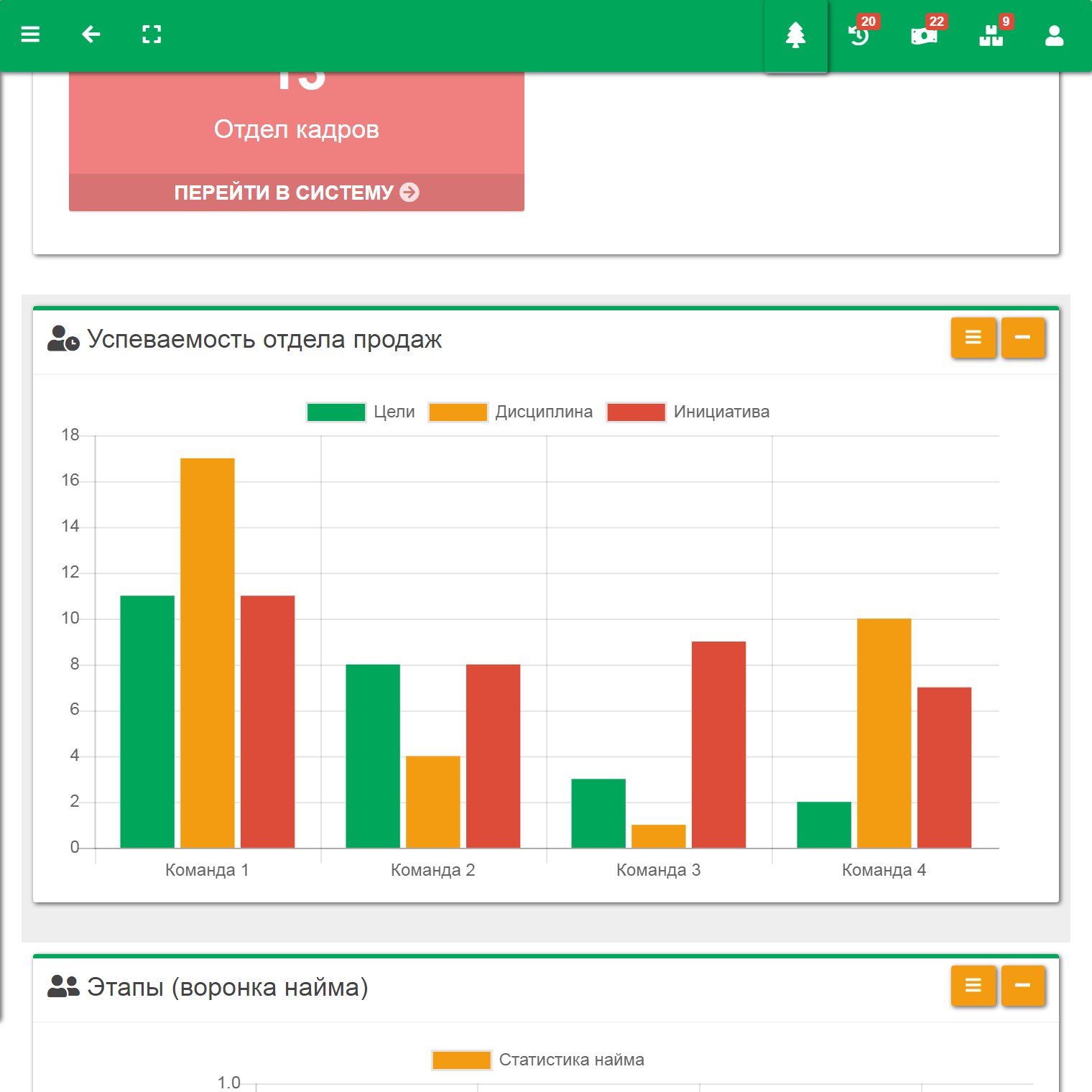
Розробка ПЗ
Розробка ПЗ
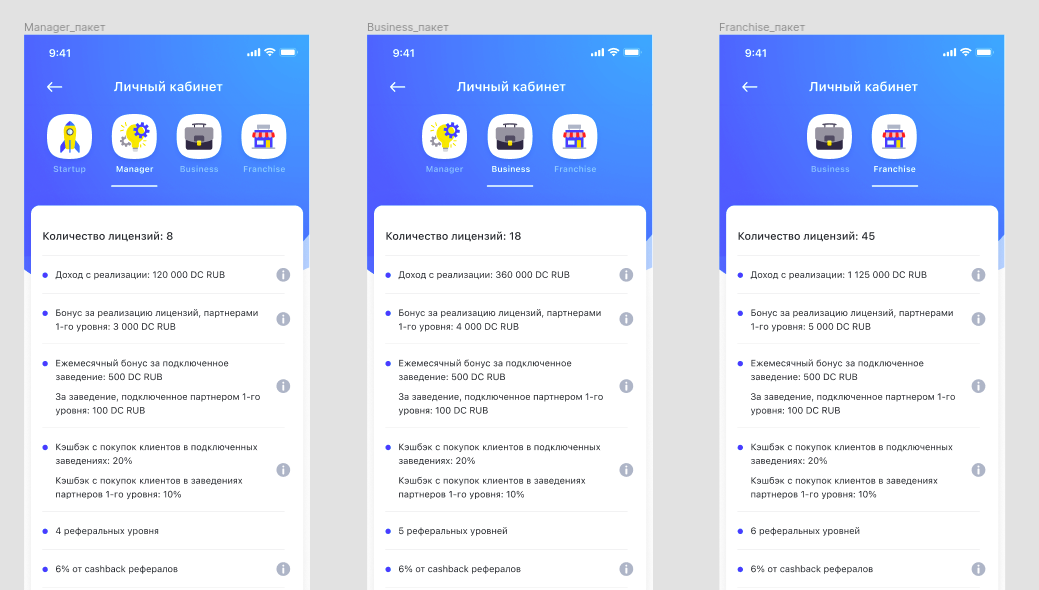
 Менеджмент
Менеджмент
 Для компаній
Для компаній
 Для стартапів
Для стартапів
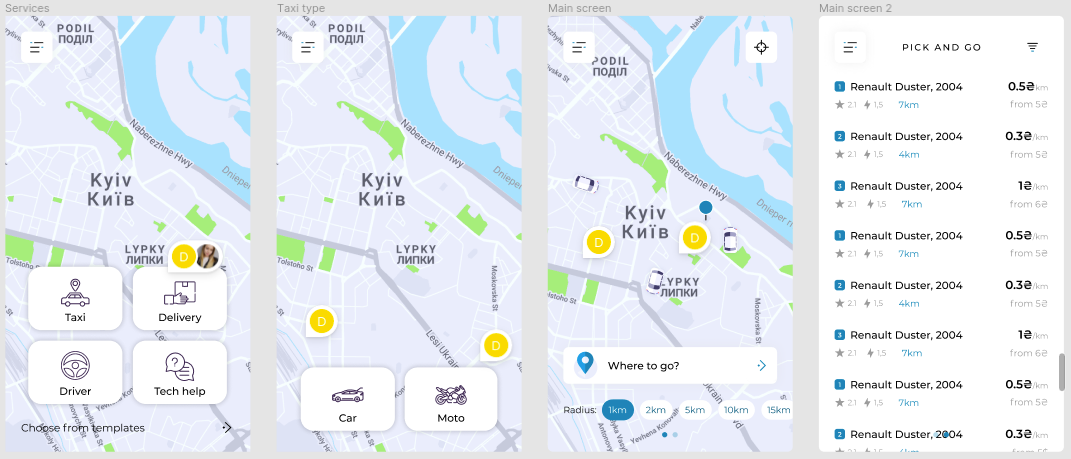
 Архітектура ПЗ
Архітектура ПЗ
Спільно з Київським Інститутом Геронтології, з кафедрою епігенетики ми вирішили робити проєкт, спрямований на науковий спосіб зробити крок у бік радикального довголіття. Я приїхав на екскурсію, мені показали лабораторії, після чого стартували проєкт. Суть проєкту - необхідно агрегувати дані з різних генетичних баз. Ці дані - -це експресія генів у різних тканинах. Тканини бралися за допомогою біопсії у різних пацієнтів (яких належало відсортувати за віковими групами). Якщо по-простому, по-колгоспному - суть проєкту в тому, щоб знайти відмінності між даними літніх і молодих людей, що дозволить припустити, як ми можемо уповільнити старіння.
https://sites.google.com/view/immortal-ingello/agi...
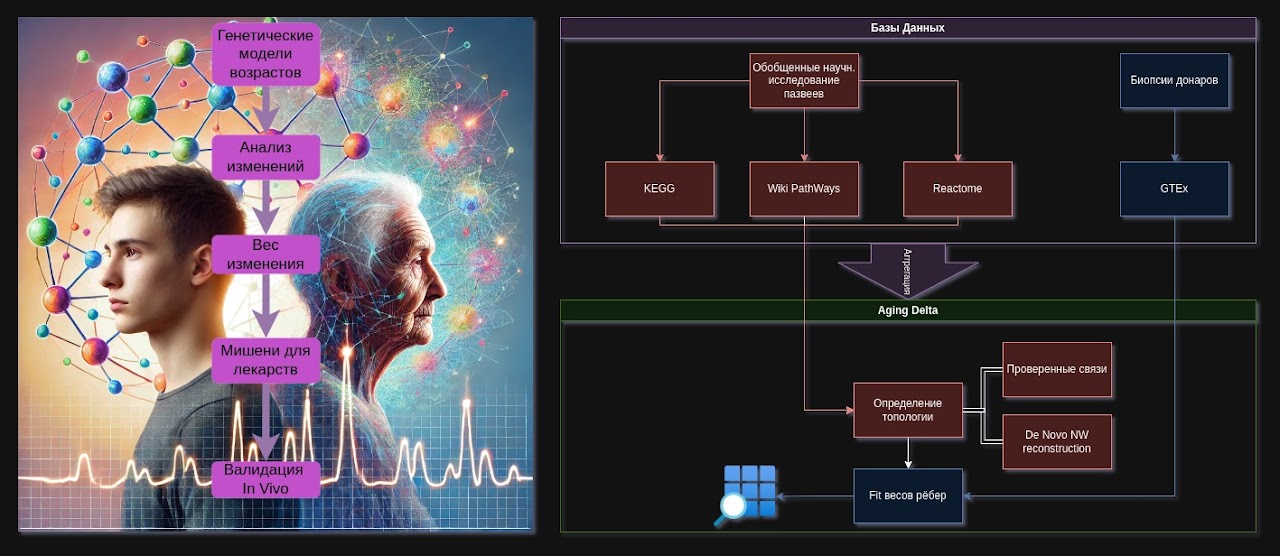
Проєкт Aging Delta спрямований на створення комплексної графової моделі змін у біологічних шляхах під час старіння, об’єднуючи дані з провідних баз знань (KEGG, Reactome, WikiPathways) і реальних профілів експресії (GTEx). Архітектура проєкту розділена на інфраструктурно-програмну та біологічно-аналітичну частини, що передбачають збір даних, їх структуризацію, побудову графів, статистичний/ML-аналіз і, нарешті, біологічну інтерпретацію результатів. Використання методів доменно-орієнтованого проєктування (DDD) допомагає команді формувати єдину мову (ubiquitous language) та ефективно взаємодіяти на стику програмування, геронтології та біоінформатики.
I.1. Загальна концепція
- Опис
- Aging Delta — це міждисциплінарний проєкт, орієнтований на дослідження процесів старіння на рівні генів, сигнальних шляхів і клітинних взаємодій.
- Проєкт об’єднує дані з кількох типів ресурсів:
- Структурні бази знань про шляхи (pathways) і сигнальні каскади (KEGG, WikiPathways, Reactome), де зберігається узагальнена інформація про те, як взаємодіють гени, білки та метаболіти.
- База даних реальної експресії (GTEx), що містить результати біопсій від різних донорів, що дозволяє зрозуміти, наскільки активно «увімкнений» або «вимкнений» кожен ген у різних тканинах і в різному віці.
- Мета
- Створити інтегровану мережеву модель (граф/графи) процесу старіння з урахуванням вікових змін.
- Оцінити внесок окремих генів і шляхів (pathways) у розвиток патологічних процесів (онкологія, нейродегенерація та ін.) і сформулювати гіпотези про «таргети» (конкретні гени/білки) для потенційних втручань (модуляції).
- Завдання
- Агрегувати дані зі структурних баз (KEGG, WikiPathways, Reactome) і зіставити їх із реальними даними експресії (GTEx).
- Побудувати два або більше графів (для різних вікових груп) або один загальний граф із різними вагами (силами зв’язків) залежно від віку.
- Виконати “фіт ребер” (визначення сили взаємодії/кореляції) на основі статистичних або ML-методів (див. статтю з PubMed, 37021935).
- Аналізувати отримані мережі з метою виявити ключові зміни в сигнальних шляхах, їх потенційний внесок у віково-асоційовані захворювання і визначити мішені для подальших досліджень (наприклад, білки, які можна модулювати хімічно або епігенетично — метилюванням, ацетилюванням, інгібіторами тощо).
I.2. Термінологія і мова предметної області (Domain-Driven Design)
- Pathway (шлях) — послідовність біохімічних реакцій або сигнальних подій (наприклад, mTOR pathway, MAPK pathway тощо).
- Ген — ділянка ДНК, що кодує білок або функціональну РНК.
- Білок (протеїн) — продукт експресії гена, що виконує структурні, ферментативні, регуляторні та інші функції.
- Експресія гена — активність гена в клітині (визначається кількістю РНК або білка).
- Таргети (targets) — потенційні точки прикладання, на які можуть впливати ліки (наприклад, гіперактивний білок, який потрібно інгібувати).
- Метилювання/Ацетилювання — основні епігенетичні механізми модуляції активності генів або білків.
- Граф — математична модель мережі взаємодій, де вузли (nodes) — це гени/білки, а ребра (edges) — їхні зв’язки (кореляція експресії, прямі фізичні взаємодії тощо).
- Фіт ребер — процес підбору або обчислення «ваги» взаємодії між двома вузлами, ґрунтуючись на експериментальних даних (наприклад, з RNA-seq).
II. Структурні бази даних і GTEx
II.1. Структурні бази (KEGG, WikiPathways, Reactome)
- KEGG (Kyoto Encyclopedia of Genes and Genomes)
- Посилання
- Містить ретельно анотовані карти шляхів, метаболізмів та інформації про взаємодії між генами і білками.
- WikiPathways
- Посилання
- Краудсорсингова платформа, де фахівці й ентузіасти спільно підтримують та оновлюють шляхи.
- Reactome
- Посилання
- База даних сигнальних шляхів із ретельною ручною анотацією і посиланнями на первинну літературу.
З цих баз ми беремо топологію (хто з ким пов’язаний) і загальну інформацію про функціональні взаємодії.
II.2. База GTEx (Genotype-Tissue Expression)
- Опис
- Посилання
- Містить «сирі» дані експресії генів (RNA-seq) з біопсій різних донорів, а також метадані (вік, стать, тканина тощо).
- Значущість
- Дозволяє побачити, як реально експресуються гени в різних тканинах і віках.
- Дані потрібні для «підгонки» ваги зв’язків (ребер) у графі, а також для виявлення патернів, характерних для старіння.
III. Архітектура і фази
III.1. Поділ на дві частини
- Частина A. (Домен програмування та архітектури)
- Збір (можливо, за допомогою скриптів і API) та очищення даних із баз.
- Організація зберігання даних (БД, файлові сховища).
- Реалізація логіки агрегації (усереднення, фільтрація, нормалізація).
- Побудова графів (структура + ваги ребер) для різних вікових груп або одного загального графа з кількома наборами ваг.
- Візуалізація мереж (JS/Canvas, D3.js або Cytoscape.js).
- Підтримка веб-інтерфейсу (керувальні панелі, вивантаження/завантаження результатів).
- Частина B. (Біо-хімія, геронтологія, статистичний/ML-аналіз)
- Застосування методів статистики і машинного навчання (WGCNA, диференціальна експресія, ко-експресійний аналіз).
- Біологічна інтерпретація отриманих мереж: пошук ключових модулів, генів, сигнальних шляхів.
- Формування гіпотез про таргети (який білок під час старіння проявляє гіперактивність або навпаки).
- Пропозиція стратегій модуляції таргета (інгібування, активація, метилювання тощо).
- Фінальна перевірка результатів у біологічних експериментах (in vitro, in vivo).
III.2. Фази проєкту
- Фаза: Системний і доменний аналіз
- Збір вимог, вивчення предметної області, практики доменно-орієнтованого проєктування (DDD).
- Фаза: Проєктування архітектури
- Розробка схеми баз даних, визначення форматів для зберігання графів, протокол взаємодії між Частиною A і Частиною B.
- Фаза: Створення прототипу
- Підняття мінімального оточення (Docker, сервер БД, PHP/JS-фронтенд).
- Імпорт тестових наборів даних (KEGG, GTEx).
- Фаза: Агрегація даних з урахуванням вікових груп
- Поділ донорів у GTEx за віковими когортами.
- Якщо потрібно — об’єднання (усереднення) експресії всередині кожної вікової групи.
- Створення (або оновлення) графа (два графи «Молодий/Старий» або один із різними вагами).
- Фаза: Нормалізація даних (за потреби)
- Усунення технічних артефактів, приведення експресій до єдиного масштабу.
- Фаза: Усереднення експресій, диференціальна кореляція або WGCNA
- Методика залежить від обраної стратегії аналізу (класична диференціальна експресія або побудова ко-експресійних мереж).
- Фаза: Порівняння (pinpoint) для різних тканин
- Пошук змін топологічних властивостей: втрата центральності, зміна кластеризації та ін.
- Фаза: Оптимізація (за потреби)
- Покращення продуктивності (великі графи, обробка великих обсягів даних).
- Фаза: Візуалізація
- Розробка інтерактивних засобів відображення (Canvas, D3.js, Cytoscape.js).
- Підсвічування змін між віками.
- Фаза: Статистичний аналіз та/або ML-методи
- Пошук закономірностей, кластерів, ключових вузлів.
- Використання алгоритмів навчання (класифікація, регресія, random forest, нейромережі).
- Фаза: Мануальний біо-клінічний аналіз
- Інтерпретація результатів фахівцями-геронтологами.
- Уточнення, які шляхи реально пов’язані з онкологією, нейродегенерацією тощо.
- Фаза: Побудова гіпотез про таргети
- Формування списку потенційних генів/білків (наприклад, гіперактивний білок, який потрібно інгібувати).
- Фаза: Гіпотези модуляції таргетів
- Пропозиція конкретних втручань (інгібітори, метилювання, ацетилювання) на молекулярному рівні.
- Фаза: Експериментальна валідація
- In vitro експерименти (використання клітинних ліній, прилади: проточний цитофлуориметр для аналізу, qPCR для підтвердження експресії, Western blot).
- In vivo експерименти (модельні тварини, спостереження за змінами фенотипу).
IV. Наявні проєкти: схожість, відмінності, синергія
- Human Ageing Genomic Resources (HAGR)
- Посилання
- Містить GenAge (база генів, пов’язаних зі старінням), AnAge (дані про тривалість життя видів).
- Допомагає виділити «кандидатні» гени для нашого аналізу.
- AgeFactDB
- Посилання (тимчасово на реконструкції)
- База даних факторів, що впливають на тривалість життя різних організмів.
- Open Targets
- Посилання
- Проєкт для пошуку і пріоритизації лікарських мішеней, але не суто про старіння, а про хвороби загалом.
- Aging.ai
- Посилання
- Модель для прогнозування віку за біомаркерами крові, менший фокус на мережевих шляхах.
- Geroprotectors.org
- База потенційних геропротекторів, але без глибокої мережевої аналітики.
Усі ці ресурси дають часткову інформацію (гени, тривалість життя, фактори), але не надають комплексної «графової» моделі, яку ми хочемо створити в Aging Delta.
V. Типові проблеми і складнощі
- Інтеграція даних
- Різнорідні формати й ідентифікатори (гени за Ensembl, HGNC, NCBI тощо).
- Вікові зрізи
- Часто немає чітких лонгітюдних даних по одній людині, доводиться усереднювати за групами.
- Відсутність реальної динаміки
- Старіння — процес, а в базах ми зазвичай маємо статичні «зрізи».
- Шуми і неповнота
- RNA-seq та інші методи дають варійовані дані, необхідна статистична фільтрація.
- Інтерпретація причин і наслідків
- Зв’язок гена з віком не означає причинно-наслідкову залежність.
- Мультидисциплінарність
- Потрібні компетенції в програмуванні, математиці, геронтології, біоінформатиці.
VI. Технологічний стек
VI.1. Програмна (інфраструктурна) частина
- Операційні середовища та інструменти
- Linux (серверне оточення), Docker (контейнеризація), Bash (скрипти автоматизації).
- Мови
- PHP (фреймворк Yii/Laravel) — бекенд для вебзастосунку.
- SQL (MySQL) — реляційна база даних для зберігання агрегованої інформації.
- HTML/CSS/JavaScript — фронтенд, візуалізація через Canvas, D3.js або Cytoscape.js.
- Архітектурні рішення
- Мікросервісний підхід або моноліт із чітким розділенням модулів (DDD — “bounded contexts”).
- REST API або GraphQL (опційно) для обміну з аналітичним модулем.
VI.2. Біоінформатична та аналітична частина
- Мови та бібліотеки
- Python: pandas, NumPy, SciPy, scikit-learn, PyTorch/TensorFlow (для ML за потреби).
- R: Bioconductor (edgeR, DESeq2, limma), WGCNA, iGraph.
- Підходи до аналізу
- Диференційна експресія (DESeq2), коекспресія (WGCNA).
- Побудова кореляційних мереж, методів “фіту ребер” (стаття PubMed 37021935).
- Графовий аналіз: центральність, кластеризація, пошук модулів.
- Додаткові інструменти
- Jupyter Notebooks/R Markdown — відтворювані дослідження.
- Git — версіонування коду та даних.
VI.3. Додаткові (маркетингові) завдання
- Інфографіка та схеми
- Створення промоматеріалів (у Figma) для залучення волонтерів, інвесторів.
- Схематичне пояснення архітектури, принципу роботи.
- Розділ сайту
- Агрегація інформації про проєкт, документація, FAQ.
- UX/UI-дизайн керівних інтерфейсів (перегляд графів, фільтрація, звіти).
- Презентація
- Підготовка слайдів, постерів для наукових конференцій або пітчів для інвесторів.
VII. Практики доменно-орієнтованого проєктування (DDD)
- Ubiquitous Language
- Використання єдиних термінів (ген, шлях, експресія, вага ребра, таргет) і однакове їх розуміння командою розробників та біологів.
- Bounded Context
- Розділення проєкту на модулі:
- «Data Aggregation Context» (завантаження та нормалізація даних),
- «Network Construction Context» (побудова графів),
- «Biological Analysis Context» (WGCNA, статистика, ML),
- «Visualization & UX Context» (вебінтерфейс).
- Розділення проєкту на модулі:
- Context Mapping
- Визначення, як ці модулі взаємодіють (API, формати даних, проміжні CSV/TSV або SQL-таблиці).
- Domain Events
- Події, такі як «дані за віковою групою оновлені», «граф перерахований», «новий модуль мережі виявлений» — можуть бути оформлені як доменні події, що впливають на логіку проєкту.
VIII. Посилання та додаткові матеріали
- KEGG
- WikiPathways
- Reactome
- GTEx Portal
- PubMed (метод фіту ваг ребер)
- Human Ageing Genomic Resources (HAGR)
- AgeFactDB
- Open Targets
- Aging.ai
- Geroprotectors.org
- Вікіпедія (терміни, визначення)
https://docs.google.com/document/d/1eEL9kFAerWu-DW...
Це допоможе розібратися з GTEx у вихідному вигляді, робив для того, щоб можна було ввести в курс справи, але це саме для того проєкту, яким займаюся, крім того доки сируваті, не найбільш чорнова версія, корисна, але багато чого не вистачає. До неї додаються різні скрипти, але там їх навіть не запустити без окремих доків на самі скрипти та інфру, а такого рівня доки тільки в голові й не на поверхні, треба згадувати
https://docs.google.com/document/d/14C07ODWNKPZXAu...
https://docs.google.com/document/d/16ji4anrUO6zZA6...
Це навряд чи стане в пригоді